Sarocha Chootipongchaivat
Moving Forward With DCIS and Invasive Breast Cancer
1 september 2026
Erasmus Universiteit Rotterdam
Open Ebook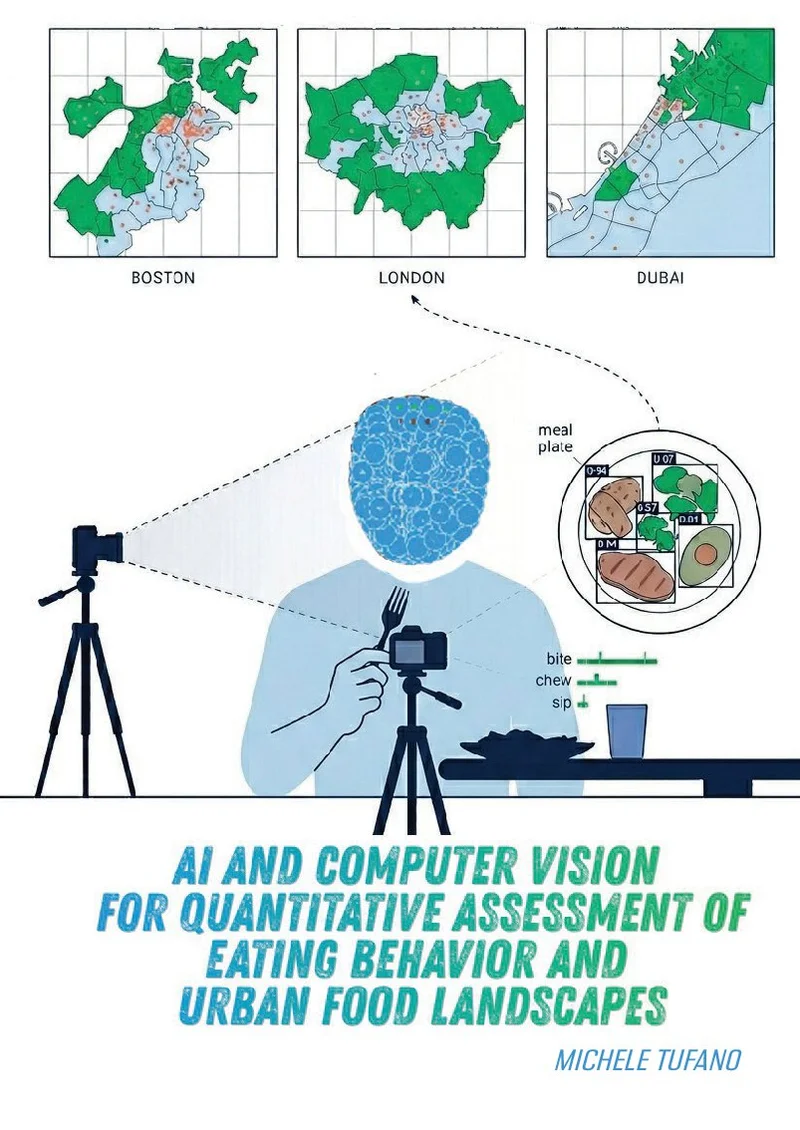
Deel dit project
Samenvatting
Eetgedrag en de toegankelijkheid van de voedselomgeving zijn fundamentele determinanten van de voedingsinname en gezondheidsuitkomsten, maar traditionele beoordelingsmethoden — handmatige video-annotatie voor eetgedrag en observationele audits voor de voedselomgeving — blijven arbeidsintensief, tijdrovend en moeilijk op te schalen. Dit proefschrift onderzocht hoe kunstmatige intelligentie de beoordeling van eetgedrag en stedelijke voedsellandschappen kan automatiseren om voedingsonderzoek op zowel individueel- als populatieniveau te ondersteunen.
Op populatieniveau werd een datagestuurde methodologie ontwikkeld om stedelijke voedsellandschappen te beoordelen met behulp van restaurantmenugegevens van online bezorgplatforms in Boston, Londen en Dubai (Hoofdstuk 2). Machine learning koppelde menu-items aan de Amerikaanse FoodData Central-database, waardoor de berekening van voedingsindices op buurtniveau mogelijk werd. De database-dekking varieerde aanzienlijk per stad — Boston (71%), Londen (56%) en Dubai (42%) — wat beperkingen in de beschikbaarheid van regiospecifieke voedingsgegevens weerspiegelt. Voedingsvezels vertoonden significante omgekeerde associaties met obesitas in zowel Londen (p=0,001) als Boston (p=0,004), terwijl buurten met een hogere sociaaleconomische status consequent een betere toegang tot voedingsrijke producten lieten zien. Deze methodologie biedt een schaalbaar alternatief voor traditionele beoordelingen van de voedselomgeving, waardoor beleidsmakers buurten kunnen identificeren die risico lopen op onvoldoende toegang tot gezonde voeding.
Op individueel niveau identificeerde een systematische review volgens de PRISMA-richtlijnen vijf methodologische categorieën voor automatische detectie van eetgedrag op basis van video-opnames: gezichtsoriëntatiepunten (facial landmarks), deep learning, optical flow, active appearance models en videofluoroscopie (Hoofdstuk 3). Gezichtsoriëntatiepunten bleken de meest veelbelovende benadering voor het detecteren van zowel happen (bites) als kauwbewegingen (chews). Voortbouwend op deze bevindingen werd een computationeel efficiënt rule-based systeem ontwikkeld dat gebruikmaakt van 468 3D-gezichtspunten voor het automatisch tellen van happen. Dit systeem behaalde een nauwkeurigheid van 79% met beschikbare annotatie en 71,4% zonder annotatie-input over 164 video's van 15 deelnemers, met consistente prestaties bij verschillende voedseltexturen (Hoofdstuk 4).
Om de nauwkeurigheid van de detectie te verbeteren, werden vervolgens op transformers gebaseerde architecturen ontwikkeld met behulp van 103 geannoteerde video's van 36 deelnemers die gestandaardiseerde maaltijden consumeerden (Hoofdstuk 5). Het Vision Transformer-model behaalde een nauwkeurigheid per frame van 98,45% en een nauwkeurigheid van 86,2% bij het tellen van happen, door effectief globale ruimtelijke relaties vast te leggen via self-attention mechanismen. Voor de detectie van kauwbewegingen presteerde een CNN-LSTM-architectuur beter dan de Vision Transformer (85,56% versus 69,21% nauwkeurigheid), omdat sequentiële modellen de temporele dynamiek die inherent is aan kauwgedrag beter vastlegden. De detectie van slokken met behulp van een getrainde VideoMAE behaalde een nauwkeurigheid van 61%, beperkt door een kleine dataset en uitdagingen bij de annotatie.
Deze gevalideerde modellen werden geïntegreerd in de Automated Meal Video Analysis (AMVA) Toolkit, een open-source cloud-native platform ingezet op een AWS serverless infrastructuur met AVG-conforme gegevensverwerking en privacy-beschermende gezichtsmaskering (Hoofdstuk 6). Het systeem verminderde de handmatige annotatietijd met een factor 40 — van zes weken naar zes uur voor 118 video's — terwijl de verwerkingsschaalbaarheid lineair bleef met de videoduur.
Dit proefschrift toont aan dat kunstmatige intelligentie de beoordeling van eetgedrag en stedelijke voedsellandschappen succesvol kan automatiseren, waardoor arbeidsintensieve handmatige processen worden getransformeerd in schaalbare, objectieve meetsystemen. Huidige beperkingen zijn onder meer geografische beperkingen in voedingsdatabases, culturele bias richting westerse voedingspatronen en onvoldoende trainingsgegevens voor drinkgedrag (Hoofdstuk 7). Toekomstig werk zou prioriteit moeten geven aan het uitbreiden van de weergave van culturele gegevens, het verbeteren van de generaliseerbaarheid van modellen over diverse eetcontexten en het ontwikkelen van geïntegreerde multimodale AI-systemen voor uitgebreide gedragsbeoordeling. Door de voedselomgeving, eetgedrag en gezondheidsuitkomsten te overbruggen, positioneert dit proefschrift kunstmatige intelligentie als een fundamentele methodologie voor schaalbare, datagestuurde voedingswetenschap, die analyses mogelijk maakt die voorheen onhaalbaar waren vanwege kosten-, tijd- en schaalbaarheidsbeperkingen.